
本文为该教程的第1部分。
如果你之前没有听说过Service Mesh,不用担心。虽然从可用文档、公开讨论和Github活跃度来看,它是一个相对较新的技术,与基于容器和微服务架构相似还没有被广泛采用,但是它将会对软件架构带来深远影响。本文将帮助您了解Service Mesh的基础知识和教程,以及如何实现它并从基础架构获益。
Service Mesh的两个主要目标是允许洞察先前不可见的服务通信层,并获取对所有微服务间像动态服务发现、负载均衡、超时、回退、重试、断路器、分布式调用链路追踪和安全策略的执行等通信逻辑的完全控制。更多细节请查看Istio流量审计和分布式链路追踪相关资料。
Kubernetes已经拥有开箱即用的“Service Mesh”。它的“service”资源,提供了针对指定需要的pod的服务发现功能和请求的负载均衡。通过在集群的每个主机上配置管理iptables规则使一个“service”生效,只允许轮询式负载均衡途径,没有重试或回退逻辑,除此之外没有其他我们可能想要的用一个现代的Service Mesh解决的功能。然而,若在集群中实现一个功能齐全的Service Mesh系统(Linkerd、Istio或Conduit),将为您提供以下可能性:
- 允许在应用层上服务间通过简单的http协议通信而不用https:Service Mesh代理将在发送端管理HTTPS封装并在接收端实现TLS终止,允许应用程序组件仅需要使用简单的http、gRPC或其他协议而不用去操心在传输途中的加密实现,Service Mesh代理将为实现加密功能。
- 执行安全策略:代理知道那些service可以访问另外一些service和endpoint并拒绝未授权的流量。
- 断路器:访问具有高延迟的过载service或者endpoint回退,防止更多的请求落在该service或endpoint上导致请求无响应。
- 延迟感知负载平衡:而代替使用轮询式负载均衡(忽略每个目标延迟),使用根据每个后端目标的响应时间更智能的负载均衡,这应该是现代服务网格的一个非常重要的特征。
- 负载均衡队列深度:根据最少访问量路由当前请求。Service Mesh精确知道所有已经发送请求,以及它们是正在处理还是已经完成。它会根据该逻辑将新的传入请求发送到具有最小队列的节点进行处理。
- 请求路由:把根据具有特定http头标记的请求路由到负载均衡后面的特定节点。允许简单的金丝雀部署测试和其他创造性用例。这是Service Mesh提供的最强大功能之一。
- 健康检查,重试预算和驱逐行为异常的节点
- 度量标准和跟踪:报告每个target的请求量、延迟指标、成功率和错误率。
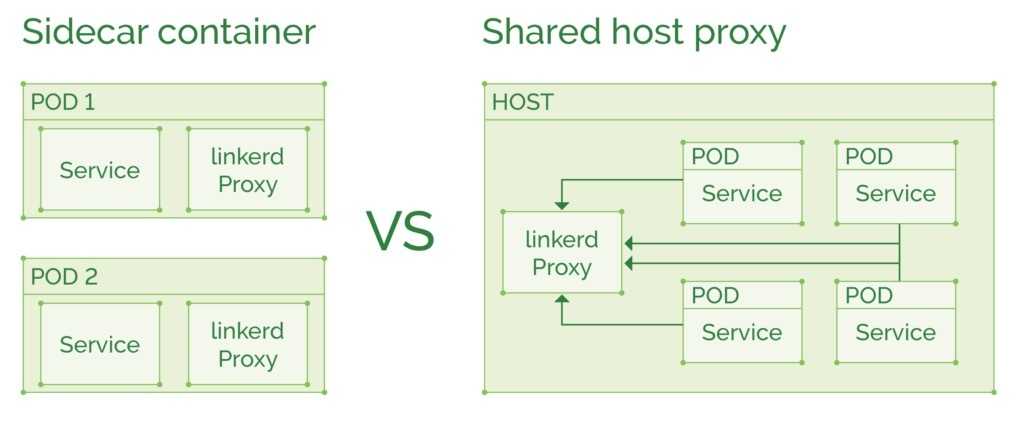
下面是两种部署Service Mesh的方式:
作为主机共享代理,Kubernetes术语中的DaemonSet。如果同一主机上存在许多容器,并且还可能利用连接池来提高吞吐量,则此类部署将使用较少的资源。但是,如果一个代理中的故障将搞垮该主机上的整个容器队列,而不是破坏单个服务(如果它被用作sidecar代理)。
作为容器sidecar,将代理注入到每个pod定义中与主服务一起运行。如果使用像Linkerd这样更加“重量级”的代理,这个部署将为每个pod增加约200MB的内存。但如果使用较新的Conduit,每个pod只需10MB左右。Conduit还没有Linkerd的所有功能,所以我们还没有看到两者的最终比较。通常,“每个pod中一个sidecar”是一个不错的选择,这样尽可能的将代理故障限制在单个pod中,不要影响同一主机上的其他pod。
为什么需要创建Service Mesh架构?让我们看一下不同类型的应用程序架构的两个图表来说明需求。
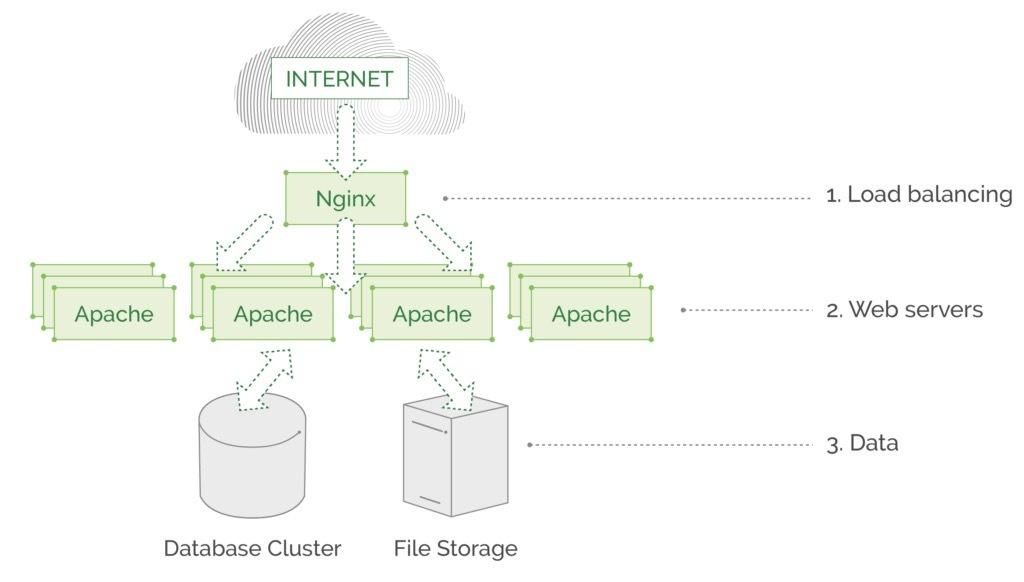
第一个示例是一个老式基于MVC架构的Web服务,是作为单体架构all-in-one应用程序。可能每天服务数百万个请求,但没有复杂的功能,并且底层服务的通信简单明了:Nginx均衡Apache实例的所有流量,Apache又从数据库/文件存储中获取数据并返回请求页面。这个示例所采用的架构不会从服务网格中获取太多收益。由于单体应用没有采用服务调用的方式,所以所有功能是耦合在一块的,开发者没有开发处理服务间路由和通信的代码。在单体应用,所有核心组件都位于同一台机器上,不通过网络进行通信,没有REST API或gRPC。所有“业务逻辑”都在一个应用程序中,在每个Apache Web服务器上作为整体部署。
第二个例子是一个基于现代微服务架构的应用程序,它有很多进程和幕后逻辑。它做了很多事情,比如学习访问者模式和偏好来个性化他们在网站上的体验,通知用户他们最喜欢的topic更新,等等。您可以想象在所有这些微服务之间发生的许多复杂过程,分布在数千个容器和数百个节点上。请注意,我们的插图非常简化。实际上,我们显示大型云原生应用程序的真实架构中简化了很多细节。
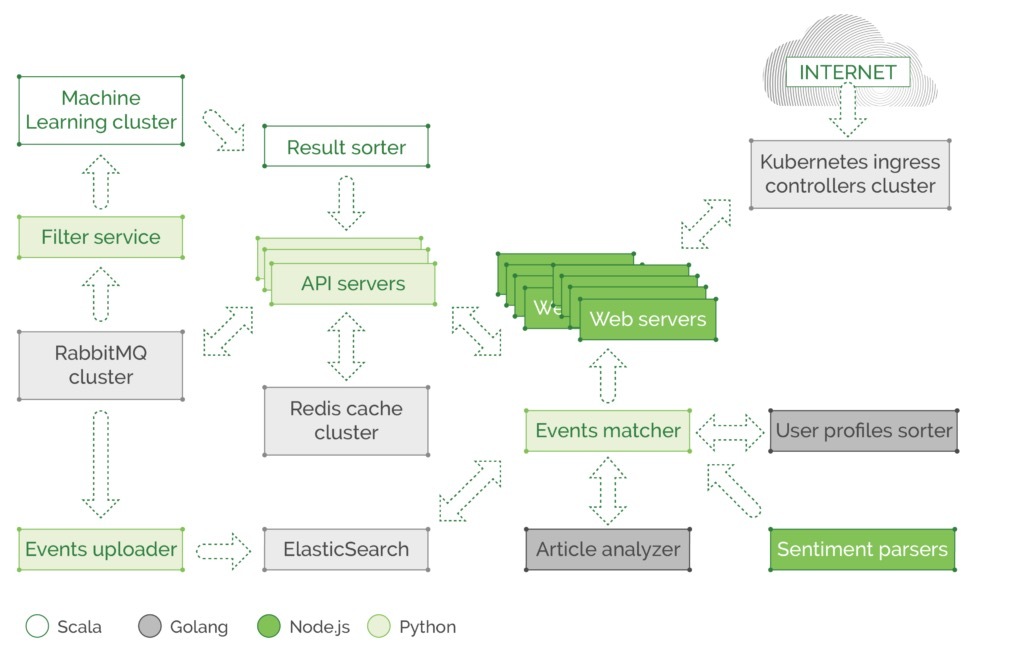
在这个实例程序中我们的每个微服务都有一些代码用于处理彼此间的通信,设置重试策略、超时、异常处理等等(在网络故障的情况下)。我们还看到这是一个多语言环境,其中不同团队使用Scala、Golang、Node.js或Python开发自己的服务组件。所有组件都可以通过REST API或gRPC相互通信,每个团队都花费时间和精力在他们自己的组件中实现通信逻辑,使用他们各自的语言选择,因此他们不能共享彼此的库和函数,至少可以节省时间并使用插入应用程序的所有组件的统一解决方案作为依赖。此外,查询服务发现机制的函数(如Consul或ZooKeeper)或读取外部传递给应用程序的一些配置,需要向Prometheus/InfluxDB报告延迟和响应相关指标。这包括有关缓存响应时间(redis或memcached缓存)的信息,该缓存响应时间通常位于另一个节点上,或者作为整个单独的群集,可能会过载并导致高延迟。除了团队爆炸日志和截止日期临近之外,所有这些都是服务代码的一部分,需要维护。开发人员不愿花时间在代码的运维相关部分任务上,例如添加分布式追踪和监控指标(不喜欢排除故障和分析)或处理可能的网络故障,实施回退和重试预算。
在这种环境中,Service Mesh将节省开发时间,并允许以统一的方式以集中式地控制通信。那我们如何将这种通信层机制改为统一的“Service Mesh”?我们把微服务间通信、路由、服务发现、延迟指标、请求追踪、和微服务中的一些相似代码完全抽取到服务外边,搞一个能够处理这些甚至更多功能的单例进程为每个微服务去处理这些公共逻辑。幸运的是这些工具已经存在,像Twitter、Lyft、Netflix这样的公司已经开源了自己的工具,其他贡献者也可以基于这些库开发自己的工具。目前为止我们有Linkerd、Conduit、Istio和Envoy供选择。Istio基于Envoy构建的,它是一个控制平面,Envoy和Linkerd都可以用作它的数据平面代理。控制平面允许集群运维人员以集中式地设置特定设置,然后将其分布在数据平面代理上并重新配置它们。
Linkerd和Conduct由Buoyant开发,开发者是一些曾经在Twitter工作的工程师。目前Linkerd是最常用的Service Mesh之一,而Conduit是从头开始专门为Kubernetes构建的轻量级sidecar,非常快速且非常适合Kubernetes环境。在撰写本文时,Conduit仍处于积极发展阶段。
让我们看一下从依赖于应用程序的通信逻辑到“Service Mesh”架构的变化。
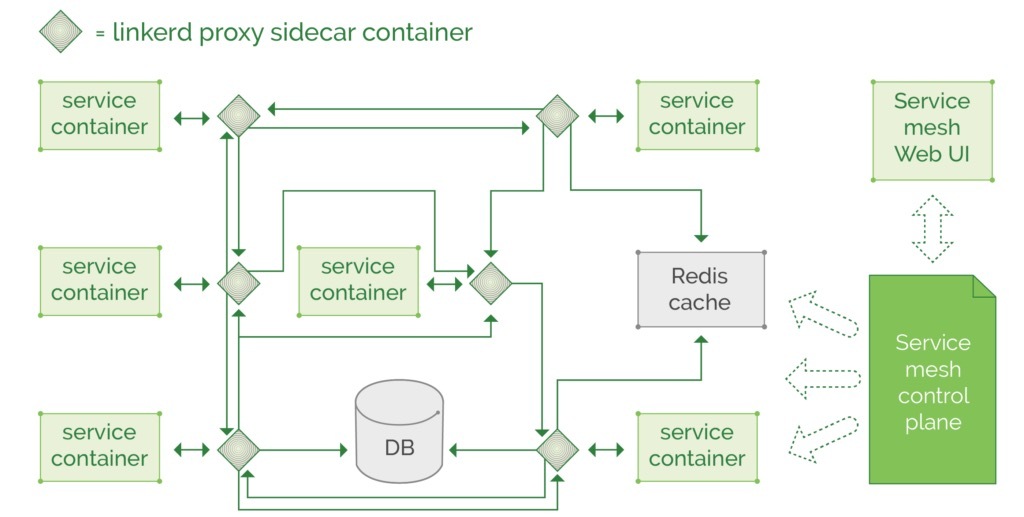
最值得注意的是,所有代理都可以在同一个地方配置和更新,通过他们的控制平面(或通过某些存储库中的配置文件, 取决于所选的工具和部署方法),我们可以在数千个代理配置特定规则。因此,路由、负载均衡、度量指标收集、安全策略实施、断路器、数据传输加密,所有这些操作都将严格遵循由集群管理员应用的一系列规则。
Service Mesh适合您吗?
乍一看,这种将微服务通信机制分离到单独的架构层的新概念引入了一个问题:是否值得配置和维护一整套复杂的特殊代理?要回答这个问题,您需要估算应用程序规模和复杂程度。如果您只有几个微服务和数据存储端点(例如,一个用于记录的ElasticSearch集群,一个用于度量的Prometheus集群,具有两个或三个主应用程序数据的数据库),那么实现服务网格可能对您的环境来说没有太大必要。但是,如果您的应用程序组件分布在数百或数千个节点上,并且具有20+微服务,采用Service Mesh你将受益匪浅。
即使在较小的环境中,如果您希望将重试和断路行为与应用程序本身分离(例如,从管理连接和退出的代码,以避免重试导致其他服务或数据库过载),您可以使用服务网格 从您的应用程序开发人员中删除此网络逻辑维护负担,你可以使用服务网格降低应用程序开发人员维护网络逻辑的负担。因此,他们将更多地关注业务逻辑,而不是参与管理和调整所有微服务的相互通信。
运维团队一旦配置服务网络,就可以集中调整,最大限度地减少在应用程序组件通信上花费的精力。
Istio是一个集中所有Service Mesh特性的完美例子,它有几个“主组件”来管理所有“数据平面”代理(这些代理可以是Envoy或Linkerd,但默认情况下,它是Envoy,这是我们在教程中使用的内容,而Linkerd集成仍在进行中)。
以下是官方网站上Istio架构的图表:
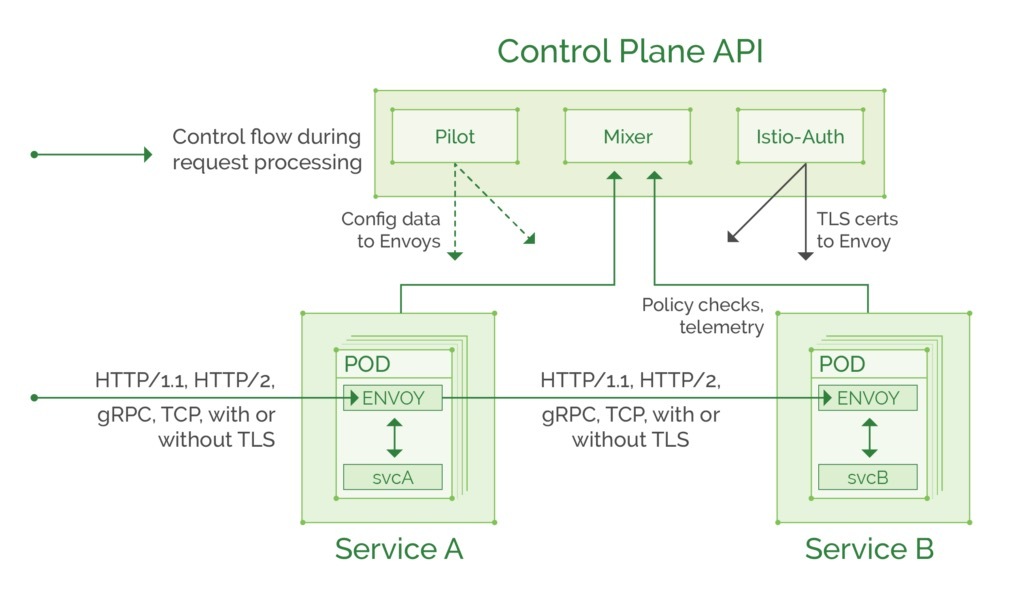
译者注:图中的istio-auth现已改名为citadel。
您可以在官方文档中阅读更多内容,但是出于本教程的目的,以下是Istio组件及其功能的摘要:
控制平面
- Pilot:向Envoy代理提供路由规则和服务发现信息。
- Mixer:从每个Envoy代理收集遥测并执行访问控制策略。
- Citadel:提供“服务间”和“用户到服务”认证,并且可以将未加密的流量基于TLS加密。很快就能提供访问审核信息(正在进行的工作)。
数据平面
- Envoy:功能丰富的代理,由控制平面组件管理。拦截进出服务的流量,并按照控制平面中设置的规则应用所需的路由和访问策略。
教程
在下面的教程中,我们将使用Istio来演示一个最强大的功能:“按请求路由”。如前面说的那样,它允许将选定HTTP头标记的特定请求路由到仅可通过第7层代理实现的特定目标。没有第4层负载均衡器或代理可以实现该功能。
对于本教程,我们假设您正在运行Kubernetes集群(提示:您可以在几分钟内遵循这些说明或启动新集群,或者使用“Kublr-in-a-box”通过几个简单的步骤设置本地群集)。对于本教程,有1个主节点和2个工作节点的小型集群应该足够了。
教程第1阶段:安装Istio控制平面
按官方教程安装在Kubernetes集群中安装控制平面。这个安装步骤依赖你的本地环境(windows、Linux还是MAC),所以我们不能复制使用本地标准指令设置应用程序,我们使用istioct和kubectl两个CLI工具管理库尔netes和istio。请安装下面简明扼要的描述去做(如果不起作用,请逐步使用官方说明):
设置kubernetes集群(使用上面列出的方法,或使用您现有的测试/开发群集)
下载kubectl并配置到环境环境(用它管理你的kubernetes环境)
下载istioctl并配置到环境变量(使用它把Envoy代理注入到每个pod中设置路由和策略)下面是简单安装说明:
(1)在MAC或Linux命令行上实行
curl -L https://git.io/getLatestIstio | sh -
(2)在windows上下载istio.zip并解压文件,将文件路径配置到你的环境变量中
(3)切换到解压环境上面文件解压路径中,并执行
kubectl apply -f install/kubernetes/istio-demo.yaml
另一种安装方式是使用Kublr安装你的kubernetes集群环境——一个简单的方法是通过云提供商(阿里云、腾讯云、aws、azure、gcp或者quick start)上拉起一个kubernetes集群。 kublr。
找到%USERPROFILE%/.kube/config文件拷贝到你的宿主机目录下(~/.kube/config),调到如下页面:
使用配置文件中的管理员账号和密码登陆到kubernetes dashboard,你应该能够看到这个仪表盘,点击侧边栏显示的default这个 namespace:
Istio组件将安装到它们自己的namespace中。调到istio下载目录,并执行命令:
kubectl apply -f install/kubernetes/istio-demo.yaml
你将看到一些列的组件被创建,详情请看官方文档或者你也可以打开yaml文件查看相应组件,每个资源都记录在该文件中。然后我们可以浏览namespace并查看所有已成功创建的内容:
在组件创建期间点击istio-system查看是否有错误或者issue,看起来应该和下面类似:
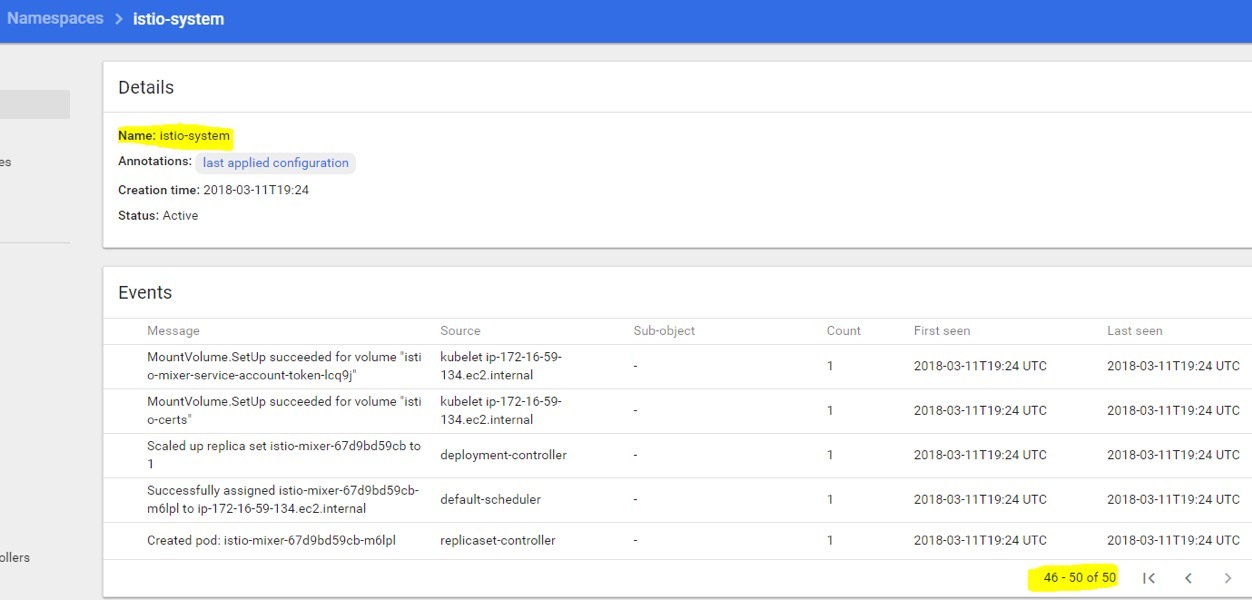
从图中可以看到有50个事件,你能滚动屏幕去看“成功”状态,并注意有些地方可能存在错误。如果有错误,你可以去github上提交issue。
我们需要找到istio-ingress服务的入口,去了解那里发送流量。回到kubernetes dashboard的侧边栏并跳转到istio-system这个namespace下。如果创建后在这个namespace下不可见,刷新浏览器试试。点击“Services”找到external endpoint,如下图所示:
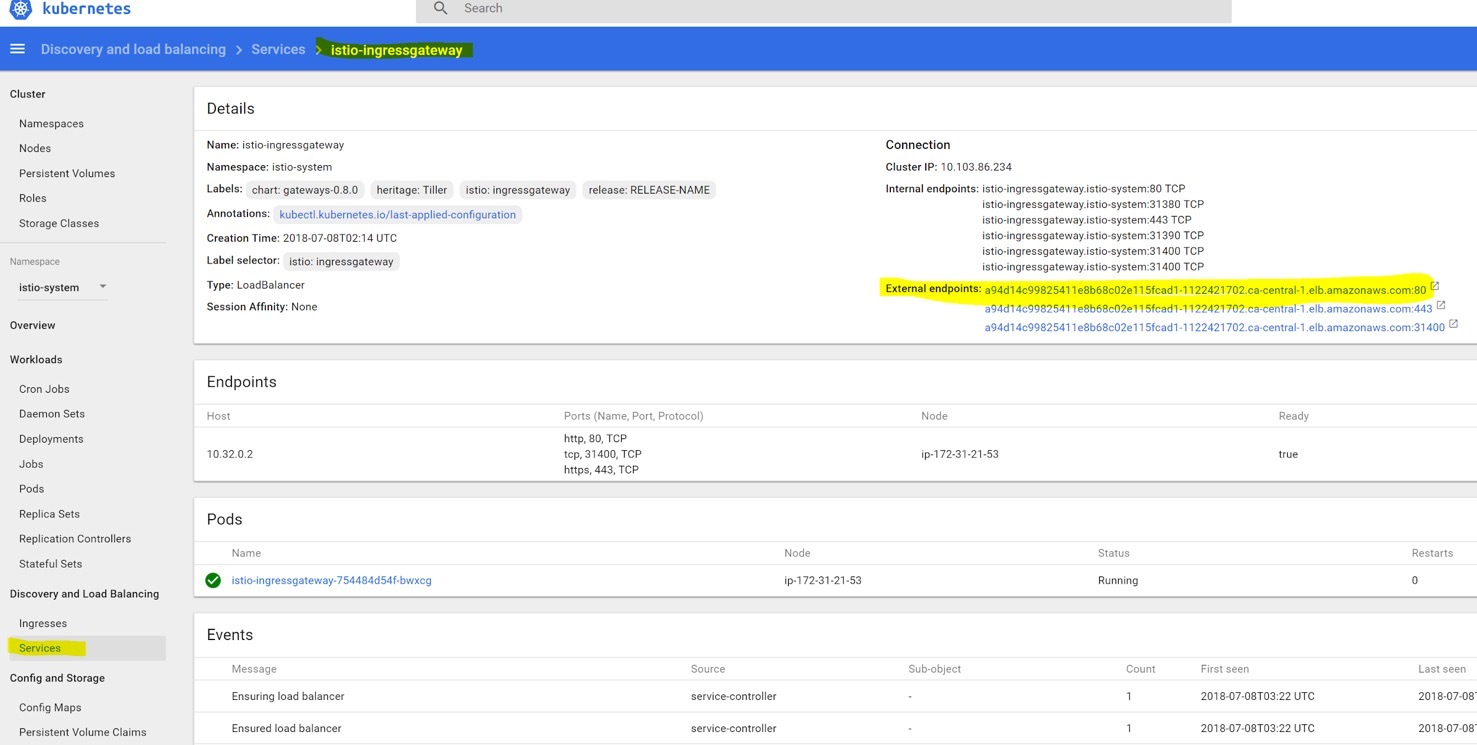
在我们的例子中,这是AWS弹性负载均衡器,但你可能会看到IP地址,具体取决于集群设置。我们将使用此端点地址访问我们的演示Web服务。
教程第2阶段:使用Envoy Sidecar部署演示Web服务
这是本教程中最好玩的部分。我们来检查一下这个Service Mesh的路由功能。首先我们将像前面一样通过蓝绿发布我们的demo实例服务。将以下内容复制到名为的my-websites.yaml文件中。
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: web-v1
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
app: website
version: website-version-1
spec:
containers:
- name: website-version-1
image: aquamarine/kublr-tutorial-images:v1
resources:
requests:
cpu: 0.1
memory: 200
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: web-v2
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
app: website
version: website-version-2
spec:
containers:
- name: website-version-2
image: aquamarine/kublr-tutorial-images:v2
resources:
requests:
cpu: 0.1
memory: 200
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: web-v3
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
app: website
version: website-version-3
spec:
containers:
- name: website-version-3
image: aquamarine/kublr-tutorial-images:v3
resources:
requests:
cpu: 0.1
memory: 200
---
apiVersion: v1
kind: Service
metadata:
name: website
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
selector:
app: website
在你的pod和Envoy代理一起使用时请注意,“app”这个label的存在(它用于请求跟踪功能),在服务中“spec.ports.name”的值要拼写正确(http、http2、grpc、redis、mongo),Enovy将像对待普通TCP一样代理这些服务,你不能对这些服务使用L7路由功能。pod在集群中只提供同一服务。从文件可以看到这个服务有三个版本(v1/v2/v3)。服务的每个版本都有对应的Deployment。
现在我们添加针对此pod的Envoy代理配置到这个文件中。使用“istioctl kube-inject”命令,它将生成一个可供kubectl部署使用包含Envoy代理额外组件的新yaml文件,运行命令:
istioctl kube-inject -f my-websites.yaml -o my-websites-with-proxy.yaml
输出文件将包含额外配置,你能查看my-websites-with-proxy.yaml文件。此命令采用预定义的ConfigMap “istio-sidecar-injector”(它在定义istio之前已经定义)。并为我们的deployment定义添加了所需的sidecar配置和参数。当我们部署新文件“my-websites-with-proxy.yaml”时,每个pod将有两个容器,一个我们的实例程序,一个Envoy代理。运行下面命令部署我们的服务程序和sidecar:
kubectl create -f my-websites-with-proxy.yaml
如果它按预期工作,您将看到此输出:
deployment "web-v1" created
deployment "web-v2" created
deployment "web-v3" created
service "website" created
Let’s inspect the pods to see that the Envoy sidecar is present: kubectl get pods
我们可以看到每个pod有两个容器,一个是网站容器,另一个是代理sidecar:

我们能够通过执行如下命令查看Envoy运行日志:
kubectl logs <your pod name> istio-proxy
您将看到很多输出,最后几行与此类似:
add/update cluster outbound|80|version-1|website.default.svc.cluster.local starting warming
add/update cluster outbound|80|version-2|website.default.svc.cluster.local starting warming
add/update cluster outbound|80|version-3|website.default.svc.cluster.local starting warming
warming cluster outbound|80|version-3|website.default.svc.cluster.local complete
warming cluster outbound|80|version-2|website.default.svc.cluster.local complete
warming cluster outbound|80|version-1|website.default.svc.cluster.local complete
这意味着sidecar在pod中运行良好。
现在我们需要部署最小的Istio配置资源,需要将路由流量到我们的service和pod。请把下面的文件保存到website-routing.yaml文件。
---
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: website-gateway
spec:
selector:
# Which pods we want to expose as Istio router
# This label points to the default one installed from file istio-demo.yaml
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
# Here we specify which Kubernetes service names
# we want to serve through this Gateway
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: website-virtual-service
spec:
hosts:
- "*"
gateways:
- website-gateway
http:
- route:
- destination:
host: website
subset: version-1
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: website
spec:
host: website
subsets:
- name: version-1
labels:
version: website-version-1
- name: version-2
labels:
version: website-version-2
- name: version-3
labels:
version: website-version-3
该文件定义了Gateway、VirtualService和DestinationRule。这些是自定义Istio资源,用于管理和配置istio-ingressgateway pod的ingress行为。我们将在下一个教程中更深入地描述它们,这些教程将阐述Istio配置的技术细节。现在,部署这些资源以便能够访问我们的示例网站:
kubectl create -f website-routing.yaml
下一步是访问我们的演示网站。我们部署了三个版本,每个都显示不同的页面文字和颜色,但目前我们只能通过Istio ingress访问v1。让我们访问我们的服务确保Web服务被部署了。
通过运行如下命令查看外部端点:
kubectl get services istio-ingressgateway -n istio-system
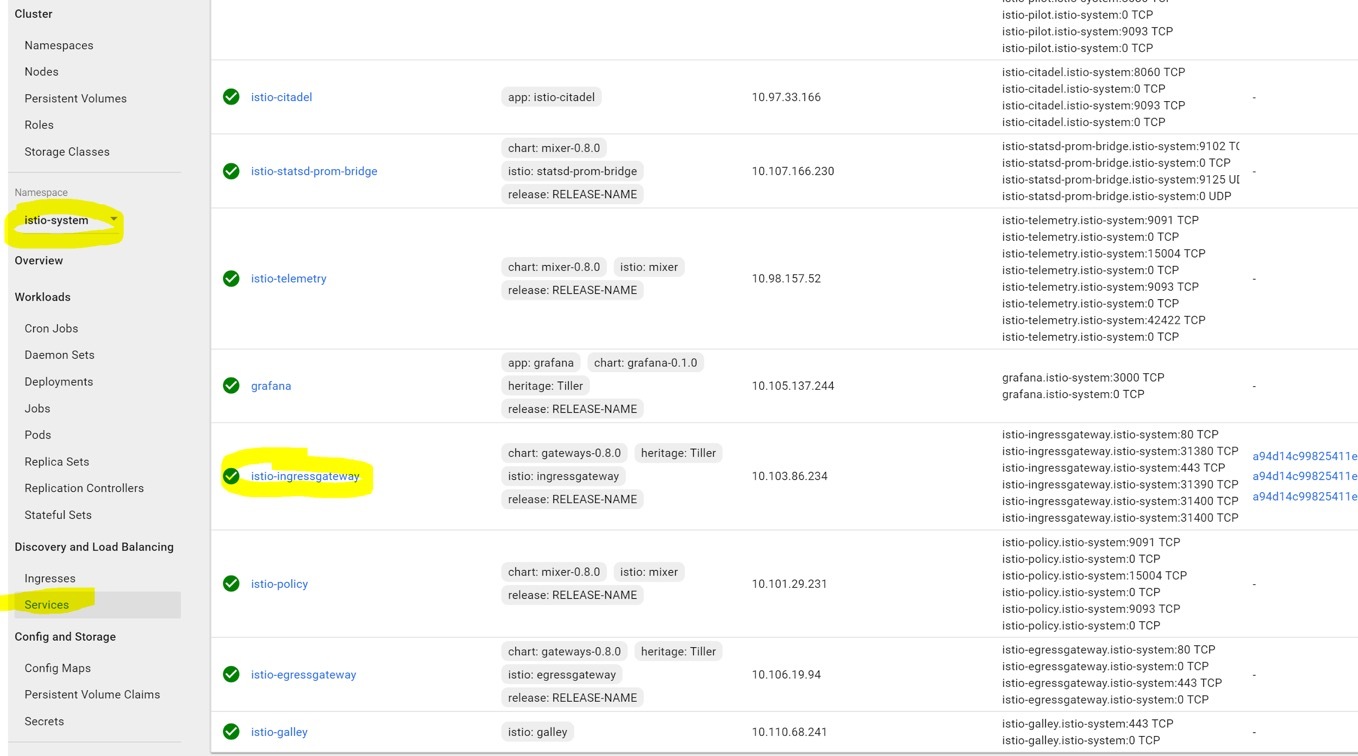
或者通过浏览istio-ingressgateway服务找到它,如下所示(我们也在本教程的开头看到过它)

通过点击它访问外部节点。您可能会看到多个链接,因为一个链接指向HTTPS,另一个链接指向负载均衡器的HTTP端口。如果是这样,请仅使用HTTP链接,因为我们没有为本教程设置TLS,您应该看到演示网站的v1页面:
为我们demo示例明确配置kubernetes service指向单一部署istio VirtualService。它指明Envoy将访问网站的流量全部路由到v1版本(如果没有Envoy路由策略,kubernetes将会在三本版本的pods轮询请求)。您可以通过更改VirtualService配置的以下部分并重新部署它来更改我们看到的网站版本:
http:
- route:
- destination:
host: website
subset: version-1
“subset”是我们选择要路由到的DestinationRule的正确地方。我们将在下一个教程中深入学习这些资源。
通常,当需要使用少量流量测试新版本的应用程序时(金丝雀部署)。vanilla Kubernetes方法使用新的Docker镜像,相同的pod标签,创建第二个deployment,将流量路由到有这个label标记的服务上。这不像Istio解决方案那样灵活。您无法轻松将10%的流量指向新deployment(为了达到精确的10%,您需要根据所需的百分比保持两个deployment之间的pod复制比例,例如9个“v1 pod”和1个“v2 pod”,或18个“v1 pod”和2个“v2 pod ”),并且不能使用HTTP头标记来将请求路由到特定版本。
在我们的下一篇文章中,与Istio一起实践的金丝雀部署,我们将自定义http头路由请求到正确的服务版本。通过这样做,我们将完全控制流量,并将分析Zipkin仪表板中的分布式追踪结果。