
本文首先向你简单介绍了 Kubernetes,然后教你从零开始构建一个 Kubernetes CRD。如果你已经对 Kubernetes 十分了解的话可以跳过本文前半部分的 Kubernetes 介绍,直接从 Controller 部分开始阅读。
快速入门Kubernetes
Kubernetes是一个容器管理系统。
具体功能:
- 基于容器的应用部署、维护和滚动升级
- 负载均衡和服务发现
- 跨机器和跨地区的集群调度
- 自动伸缩
- 无状态服务和有状态服务
- 广泛的 Volume 支持
- 插件机制保证扩展性
通过阅读Kubernetes指南和Kubernetes HandBook以及官方文档 或者 阅读 Kubernetes权威指南可以获得更好的学习体验。
在开始安装Kubernetes之前,我们需要知道:
1、Docker与Kubernetes
Docker是一个容器运行时的实现,Kubernetes依赖于某种容器运行时的实现。
2、Pod
Kubernetes中最基本的调度单位是Pod,Pod从属于Node(物理机或虚拟机),Pod中可以运行多个Docker容器,会共享 PID、IPC、Network 和 UTS namespace。Pod在创建时会被分配一个IP地址,Pod间的容器可以互相通信。
3、Yaml
Kubernetes中有着很多概念,它们都算做是一种对象,如Pod、Deployment、Service等,都可以通过一个yaml文件来进行描述,并可以对这些对象进行CRUD操作(对应REST中的各种HTTP方法)。
下面一个Pod的yaml文件示例:
apiVersion: v1
kind: Pod
metadata:
name: my-nginx-app
labels:
app: my-nginx-app
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
kind:对象的类别
metadata:元数据,如Pod的名称,以及标签Label【用于识别一系列关联的Pod,可以使用 Label Selector 来选择一组相同 label 的对象】
spec:希望Pod能达到的状态,在此体现了Kubernetes的声明式的思想,我们只需要定义出期望达到的状态,而不需要关心如何达到这个状态,这部分工作由Kubernetes来完成。这里我们定义了Pod中运行的容器列表,包括一个nginx容器,该容器对外暴露了80端口。
4、Node
Node 是 Pod 真正运行的主机,可以是物理机,也可以是虚拟机。为了管理 Pod,每个 Node 节点上至少要运行 container runtime、kubelet 和 kube-proxy 服务。
5、Deployment
Deployment用于管理一个无状态应用,对应一个Pod的集群,每个Pod的地位是对等的,对Deployment来说只是用于维护一定数量的Pod,这些Pod有着相同的Pod模板。
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-app
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx-app
template:
metadata:
labels:
app: my-nginx-app
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
可以对Deployment进行部署、升级、扩缩容等操作。
6、Service
Service用于将一组Pod暴露为一个服务。
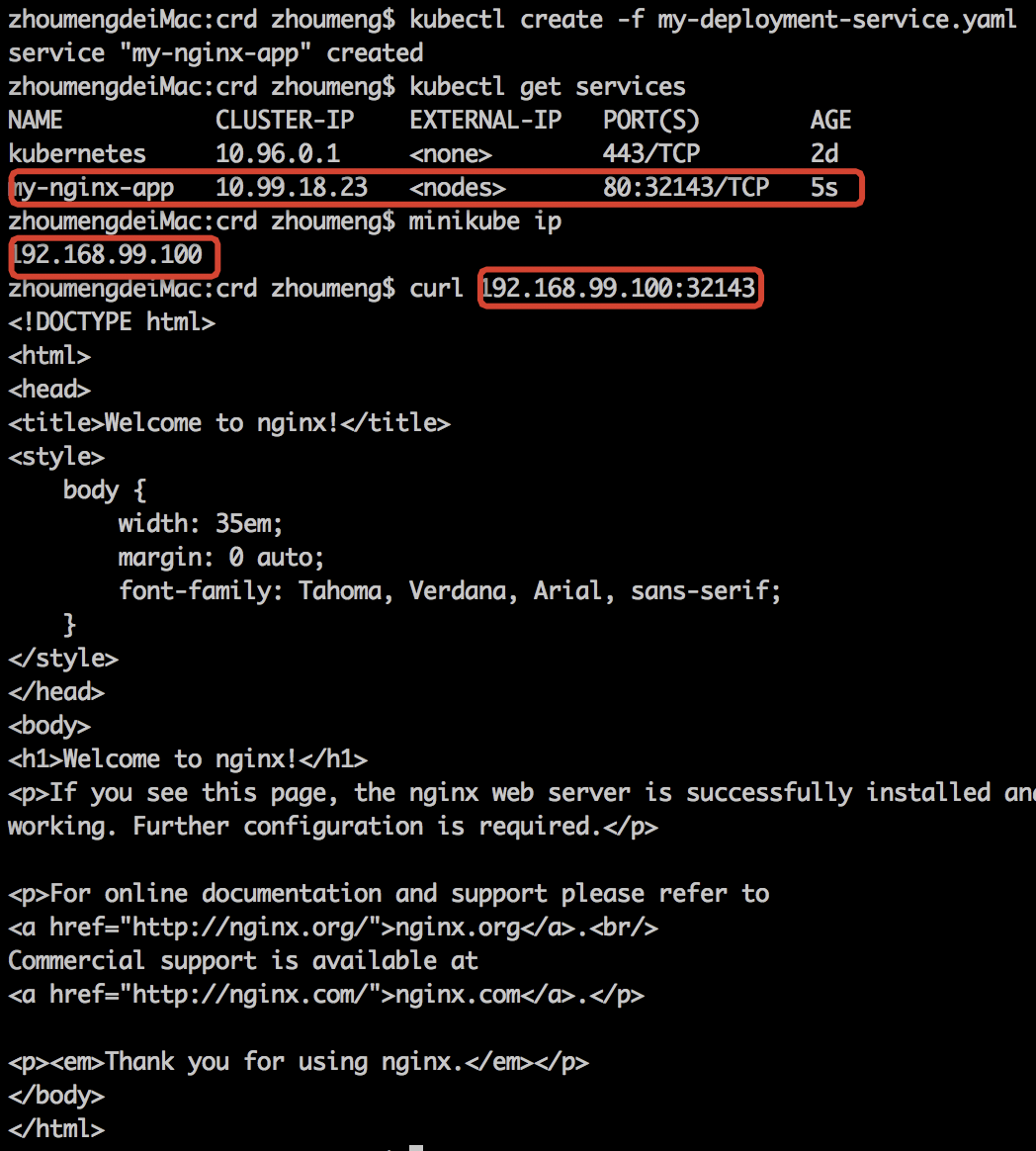
在 kubernetes 中,Pod 的 IP 地址会随着 Pod 的重启而变化,并不建议直接拿 Pod 的 IP 来交互。那如何来访问这些 Pod 提供的服务呢?使用 Service。Service 为一组 Pod(通过 labels 来选择)提供一个统一的入口,并为它们提供负载均衡和自动服务发现。
apiVersion: v1
kind: Service
metadata:
name: my-nginx-app
labels:
name: my-nginx-app
spec:
type: NodePort #这里代表是NodePort类型的
ports:
- port: 80 # 这里的端口和clusterIP(10.97.114.36)对应,即10.97.114.36:80,供内部访问。
targetPort: 80 # 端口一定要和container暴露出来的端口对应
protocol: TCP
nodePort: 32143 # 每个Node会开启,此端口供外部调用。
selector:
app: my-nginx-app
7、Kubernetes组件
- etcd 保存了整个集群的状态;
- apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
- controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上;
- kubelet 负责维护容器的生命周期,同时也负责 Volume(CVI)和网络(CNI)的管理;
- Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI);
- kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡
安装Kubernetes【Minikube】
minikube为开发或者测试在本地启动一个节点的kubernetes集群,minikube打包了和配置一个linux虚拟机、docker与kubernetes组件。
Kubernetes集群是由Master和Node组成的,Master用于进行集群管理,Node用于运行Pod等workload。而minikube是一个Kubernetes集群的最小集。
1、安装virtualbox
https://www.virtualbox.org/wiki/Downloads
2、安装minikube
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
3、启用dashboard(web console)【可选】
minikube addons enable dashboard
开启dashboard
4、启动minikube
minikube start
start之后可以通过minikube status来查看状态,如果minikube和cluster都是Running,则说明启动成功。
5、查看启动状态
kubectl get pods
kubectl体验【以一个Deployment为例】
kubectl是一个命令行工具,用于向API Server发送指令。
我们以部署、升级、扩缩容一个Deployment、发布一个Service为例体验一下Kubernetes。
命令的通常格式为:
kubectl $operation $object_type(单数or复数) $object_name other params
- operation如get,replace,create,expose,delete等。
- object_type是操作的对象类型,如pods,deployments,services
- object_name是对象的name
- 后面可以加一些其他参数
kubectl命令表:
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
http://docs.kubernetes.org.cn/490.html
Deployment的文档:
https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
https://kubernetes.feisky.xyz/he-xin-yuan-li/index-2/deployment
1、创建一个Deployment
可以使用kubectl run来运行,也可以基于现有的yaml文件来create。
kubectl run –image=nginx:1.7.9 nginx-app –port=80
或者
kubectl create -f my-nginx-deployment.yaml
my-nginx-deployment是下面这个yaml文件的名称
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-app
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx-app
template:
metadata:
labels:
app: my-nginx-app
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
然后可以通过kubectl get pods 来查看创建好了的3个Pod。
Pod的名称是以所属Deployment名称为前缀,后面加上唯一标识。

再通过kubectl get deployments来查看创建好了的deployment。

这里有4列,分别是:
- DESIRED:Pod副本数量的期望值,即Deployment里面定义的replicas
- CURRENT:当前Replicas的值
- UP-TO-DATE:最新版本的Pod的副本梳理,用于指示在滚动升级的过程中,有多少个Pod副本已经成功升级
- AVAILABLE:集群中当前存活的Pod数量
2、删除掉任意一个Pod
Deployment自身拥有副本保持机制,会始终将其所管理的Pod数量保持为spec中定义的replicas数量。
kubectl delete pods $pod_name
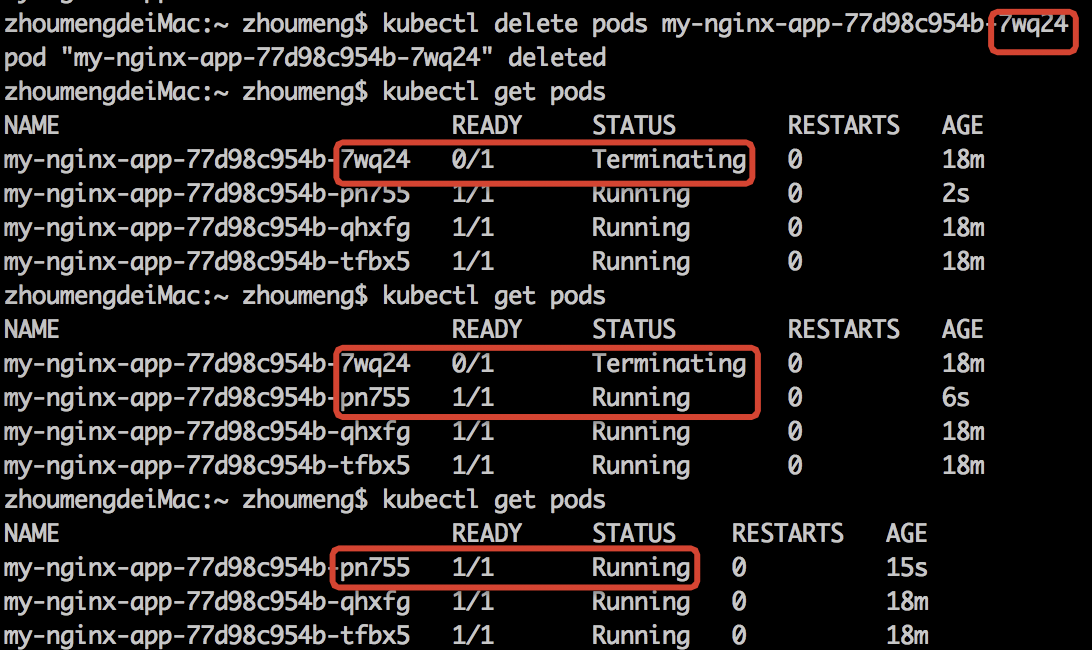
可以看出被删掉的Pod的关闭与代替它的Pod的启动过程。
3、缩扩容
缩扩容有两种实现方式,一种是修改yaml文件,将replicas修改为新的值,然后kubectl replace -f my-nginx-deployment.yaml;
另一种是使用scale命令:kubectl scale deployment $deployment_name –replicas=5
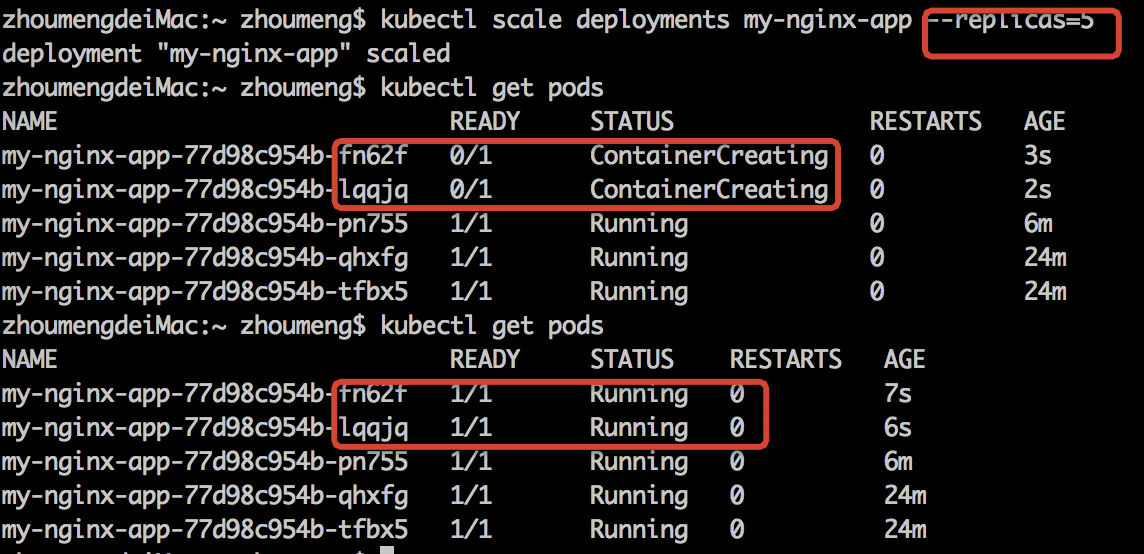
4、更新
更新也是有两种实现方式,Kubernetes的升级可以实现无缝升级,即不需要进行停机。
一种是rolling-update方式,重建Pod,edit/replace/set image等均可以实现。比如说我们可以修改yaml文件,然后kubectl replace -f my-nginx-deployment.yaml,也可以kubectl set image $resource_type/$resource_name $container_name=nginx:1.9.1
另一种是patch方式,patch不会去重建Pod,Pod的IP可以保持。
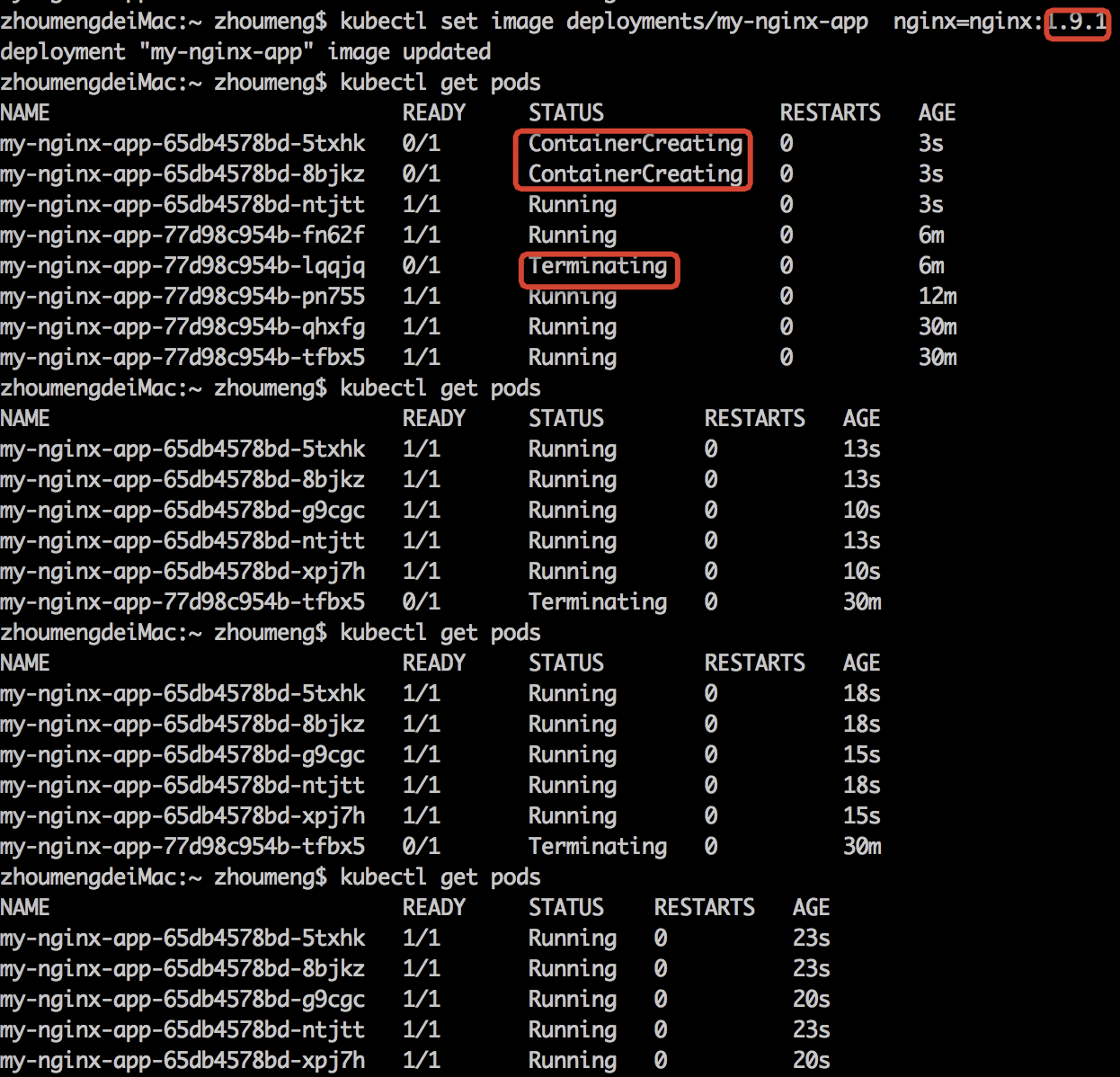
kubectl get pods -o yaml可以以yaml的格式来查看Pod
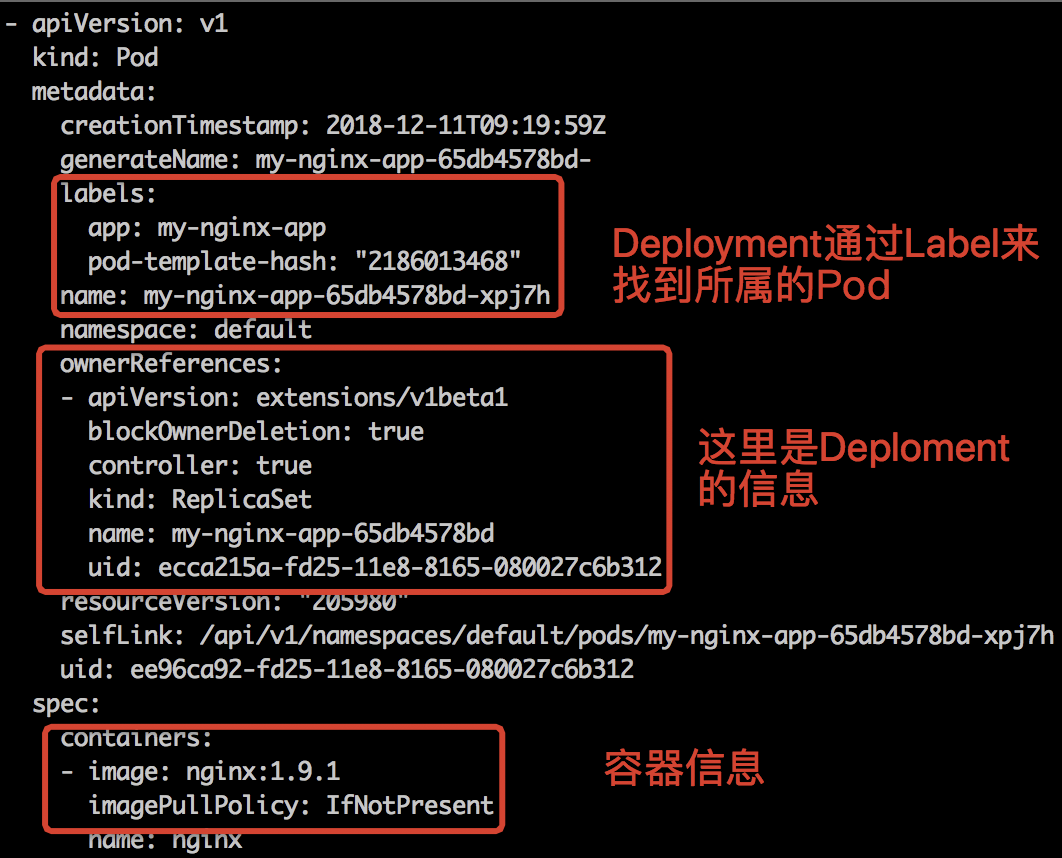
这里可以看出容器的版本已经被更新到了1.9.1。
5、暴露服务
暴露服务也有两种实现方式,一种是通过kubectl create -f my-nginx-service.yaml可以创建一个服务:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-app
labels:
name: my-nginx-app
spec:
type: NodePort #这里代表是NodePort类型的
ports:
- port: 80 # 这里的端口和clusterIP(10.97.114.36)对应,即10.97.114.36:80,供内部访问。
targetPort: 80 # 端口一定要和container暴露出来的端口对应
protocol: TCP
nodePort: 32143 # 每个Node会开启,此端口供外部调用。
selector:
app: my-nginx-app
ports中有三个端口,第一个port是Pod供内部访问暴露的端口,第二个targetPort是Pod的Container中配置的containerPort,第三个nodePort是供外部调用的端口。
另一种是通过kubectl expose命令实现。
minikube ip返回的就是minikube所管理的Kubernetes集群所在的虚拟机ip。
minikube service my-nginx-app –url也可以返回指定service的访问URL。
CRD【CustomResourceDefinition】
CRD是Kubernetes为提高可扩展性,让开发者去自定义资源(如Deployment,StatefulSet等)的一种方法。
Operator=CRD+Controller。
CRD仅仅是资源的定义,而Controller可以去监听CRD的CRUD事件来添加自定义业务逻辑。
关于CRD有一些链接先贴出来:
- 官方文档:https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/
- CRD Yaml的Schema:https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.13/#customresourcedefinition-v1beta1-apiextensions-k8s-io
- https://kubernetes.feisky.xyz/cha-jian-kuo-zhan/api/customresourcedefinition
- https://sq.163yun.com/blog/article/174980128954048512
- https://book.kubebuilder.io/
如果说只是对CRD实例进行CRUD的话,不需要Controller也是可以实现的,只是只有数据,没有针对数据的操作。
一个CRD的yaml文件示例:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
# name must match the spec fields below, and be in the form: <plural>.<group>
name: crontabs.stable.example.com
spec:
# group name to use for REST API: /apis/<group>/<version>
group: stable.example.com
# list of versions supported by this CustomResourceDefinition
version: v1beta1
# either Namespaced or Cluster
scope: Namespaced
names:
# plural name to be used in the URL: /apis/<group>/<version>/<plural>
plural: crontabs
# singular name to be used as an alias on the CLI and for display
singular: crontab
# kind is normally the CamelCased singular type. Your resource manifests use this.
kind: CronTab
# shortNames allow shorter string to match your resource on the CLI
shortNames:
- ct
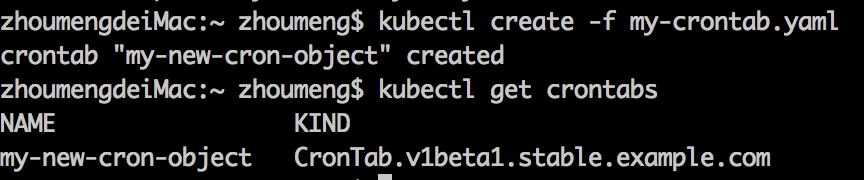
通过kubectl create -f crd.yaml可以创建一个CRD。
kubectl get CustomResourceDeinitions可以获取创建的所有CRD。

然后可以通过kubectl create -f my-crontab.yaml可以创建一个CRD的实例:
apiVersion: "stable.example.com/v1beta1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
Controller【Fabric8】
如何去实现一个Controller呢?
可以使用Go来实现,并且不论是参考资料还是开源支持都非常好,推荐有Go语言基础的优先考虑用client-go来作为Kubernetes的客户端,用KubeBuilder来生成骨架代码。一个官方的Controller示例项目是sample-controller。
对于Java来说,目前Kubernetes的JavaClient有两个,一个是Jasery,另一个是Fabric8。后者要更好用一些,因为对Pod、Deployment都有DSL定义,而且构建对象是以Builder模式做的,写起来比较舒服。
Fabric8的资料目前只有https://github.com/fabric8io/kubernetes-client,注意看目录下的examples。
这些客户端本质上都是通过REST接口来与Kubernetes API Server通信的。
Controller的逻辑其实是很简单的:监听CRD实例(以及关联的资源)的CRUD事件,然后执行相应的业务逻辑
MyDeployment
基于Fabric8来开发一个较为完整的Controller的示例目前我在网络上是找不到的,下面MyController的实现也是一步步摸索出来的,难免会有各种问题=.=,欢迎大佬们捉虫。
用例
代码在https://github.com/songxinjianqwe/deployment-controller。
MyDeployment是用来模拟Kubernetes提供的Deployment的简化版实现,目前可以做到以下功能:
- 启动后自动创建出一个MyDeployment的CRD
- 【触发】启动应用
- 【期望】可以看到创建出来的CRD
- 【测试】kubectl get CustomResourceDefinition -o yaml
- 创建一个MyDeployment: Nginx实例
- 【触发】kubectl create -f my-deployment-instance.yaml
- 【期望】可以看到级联创建出来的3个pod
- 【测试】kubectl get pods
- 手工删掉一个pod
- 【触发】kubectl delete pods $pod_name
- 【期望】pod被重建
- 【测试】kubectl get pods -w
- 暴露一个服务
- 【触发】kubectl create -f my-deployment-service.yaml
- 【期望】可以通过curl来访问nginx服务
- 【测试】minikube service my-nginx-app –url 然后 curl
- 更新镜像
- 【触发】kubectl replace -f my-deployment-instance-update-image-1.9.1.yaml
- 【期望】pod的nginx版本被更新为1.9.1
- 【测试】kubectl get pods -o yaml
- 扩容
- 【触发】kubectl replace -f my-deployment-instance-update-scaleup-1.9.1.yaml
- 【期望】pod被扩容到5个
- 【测试】kubectl get pods
- 缩容
- 【触发】kubectl replace -f my-deployment-instance-update-scaledown-1.9.1.yaml
- 【期望】pod被缩容到2个
- 【测试】kubectl get pods
- 扩容并更新镜像
- 【触发】kubectl replace -f my-deployment-instance-update-image-and-scaleup-1.14.yaml
- 【期望】pod被扩容5个,且nginx版本被更新为1.14
- 【测试】kubectl get pods 然后 kubectl get pods -o yaml
- 删除一个MyDeployment
- 【触发】kubectl delete mydeployments my-nginx-app
- 【期望】MyDeployment被删掉,并且关联的pod也被级联删掉
- 【测试】kubectl get mydeployments 然后 kubectl get pods
此外还有一些功能尚未开发,其中状态是非常重要的,很可惜时间不够没有开发完成:
- 查看状态(TODO)
- 回滚(TODO)
- 状态更新【current,update-to-date,available】(TODO)
- describe EVENTS(TODO)
运行
1、搭建好上面的minikube环境后
2、拉下deployment-controller的代码,是一个SpringBoot工程。
3、启动kube-proxy
kubectl proxy –port=12000
这一步是为了绕开Kubernetes API Server的权限认证。开启proxy之后就可以通过localhost:12000来连接Kubernetes了。
4、运行DeploymentControllerApplication的main方法即可。
5、此时可以根据上述用例来进行测试。
MyDeployment实现
项目工程结构

CRD定义
按照Fabric8的逻辑,定义一个CRD需要至少定义以下内容:
- CustomResourceDefinition,需要继承CustomResource,CRD资源定义
- CustomResourceDefinitionList,需要继承CustomResourceList,CRD资源列表
- CustomResourceDefinitionSpec,需要实现KubernetesResource接口,CRD资源的Spec
- DoneableCustomResourceDefinition,需要继承CustomResourceDoneable,CRD资源的修改Builder
- 【可选】CustomResourceDefinitionStatus(需要说明一点的是,CRD支持使用SubResource,包括scale和status,在1.11+之后可以直接使用,在1.10中需要修改API Server的启动参数来启用;minikube的最新版本是可以支持到Kubernetes的1.10的)
在CRD定义中通常是需要持有一个Spec的【注意,上面提到的所有类定义持有的成员变量最好都加一个@JsonProperty注解,不加的话在get资源时对JSON反序列化时用到的名字就是属性名了】
下面是基于Fabric8的API构建出了一个CRD,之后可以调用API将其创建到Kubernetes,效果和kubectl create -f 是一样的。
但Controller需要做到的是启动时自动创建一个CRD出来,所以用kubectl创建不够自动化。
public static final String CRD_GROUP = "cloud.alipay.com";
public static final String CRD_SINGULAR_NAME = "mydeployment";
public static final String CRD_PLURAL_NAME = "mydeployments";
public static final String CRD_NAME = CRD_PLURAL_NAME + "." + CRD_GROUP;
public static final String CRD_KIND = "MyDeployment";
public static final String CRD_SCOPE = "Namespaced";
public static final String CRD_SHORT_NAME = "md";
public static final String CRD_VERSION = "v1beta1";
public static final String CRD_API_VERSION = "apiextensions.k8s.io/" + CRD_VERSION;
public static CustomResourceDefinition MY_DEPLOYMENT_CRD = new CustomResourceDefinitionBuilder()
.withApiVersion(CRD_API_VERSION)
.withNewMetadata()
.withName(CRD_NAME)
.endMetadata()
.withNewSpec()
.withGroup(CRD_GROUP)
.withVersion(CRD_VERSION)
.withScope(CRD_SCOPE)
.withNewNames()
.withKind(CRD_KIND)
.withShortNames(CRD_SHORT_NAME)
.withSingular(CRD_SINGULAR_NAME)
.withPlural(CRD_PLURAL_NAME)
.endNames()
.endSpec()
.withNewStatus()
.withNewAcceptedNames()
.addToShortNames(new String[]{"availableReplicas", "replicas", "updatedReplicas"})
.endAcceptedNames()
.endStatus()
.build();
Controller
入口处需要去为我们的CRD注册一个反序列化器。
入口处
static {
KubernetesDeserializer.registerCustomKind(MyDeployment.CRD_GROUP + "/" + MyDeployment.CRD_VERSION, MyDeployment.CRD_KIND, MyDeployment.class);
}
/**
* 入口
*/
public void run() {
// 创建CRD
CustomResourceDefinition myDeploymentCrd = createCrdIfNotExists();
// 监听Pod的事件
watchPod();
// 监听MyDeployment的事件
watchMyDeployment(myDeploymentCrd);
}
watchPod是监听MyDeployment所管理的Pod的CRUD事件。
private void watchPod() {
delegate.client().pods().watch(new Watcher<Pod>() {
@Override
public void eventReceived(Action action, Pod pod) {
// 如果是被MyDeployment管理的Pod
if(pod.getMetadata().getOwnerReferences().stream().anyMatch(ownerReference -> ownerReference.getKind().equals(MyDeployment.CRD_KIND))) {
unifiedPodWatcher.eventReceived(action, pod);
}
}
@Override
public void onClose(KubernetesClientException e) {
log.error("watching pod {} caught an exception {}", e);
}
});
}
UnifiedPodWatcher是处理了所有Pod的事件,然后在收到事件时去通知Pod事件的订阅者,这里用到了一个观察者模式。
@Component
public class UnifiedPodWatcher {
@Autowired
private List<PodAddedWatcher> podAddedWatchers;
@Autowired
private List<PodModifiedWatcher> podModifiedWatchers;
@Autowired
private List<PodDeletedWatcher> podDeletedWatchers;
/**
* 将Pod事件统一收到此处
* @param action
* @param pod
*/
public void eventReceived(Watcher.Action action, Pod pod) {
log.info("Thread {}: PodWatcher: {} => {}, {}", Thread.currentThread().getId(), action, pod.getMetadata().getName(), pod);
switch (action) {
case ADDED:
podAddedWatchers.forEach(watcher -> watcher.onPodAdded(pod));
break;
case MODIFIED:
podModifiedWatchers.forEach(watcher -> watcher.onPodModified(pod));
break;
case DELETED:
podDeletedWatchers.forEach(watcher -> watcher.onPodDeleted(pod));
break;
default:
break;
}
}
}
Fabric8的watcher是在代码层面不会限制在多个地方去监听同一个对象的,但经粗略测试,多处监听只有在第一个地方会收到回调;从可维护性角度来说,散落在各个地方的watcher代码也是不够优雅的。所以将watcher统一收口到一个地方,然后在这个地方下发事件。
然后MyDeployment的监听也是比较类似的:
private void watchMyDeployment(CustomResourceDefinition myDeploymentCrd) {
MixedOperation<MyDeployment, MyDeploymentList, DoneableMyDeployment, Resource<MyDeployment, DoneableMyDeployment>> myDeploymentClient = delegate.client().customResources(myDeploymentCrd, MyDeployment.class, MyDeploymentList.class, DoneableMyDeployment.class);
myDeploymentClient.watch(new Watcher<MyDeployment>() {
@Override
public void eventReceived(Action action, MyDeployment myDeployment) {
log.info("myDeployment: {} => {}" , action , myDeployment);
if(myDeploymentHandlers.containsKey(MyDeploymentActionHandler.RESOURCE_NAME + action.name())) {
myDeploymentHandlers.get(MyDeploymentActionHandler.RESOURCE_NAME + action.name()).handle(myDeployment);
}
}
@Override
public void onClose(KubernetesClientException e) {
log.error("watching myDeployment {} caught an exception {}", e);
}
});
}
创建MyDeployment的实现逻辑
创建MyDeployment时会创建出replicas个Pod出来。此处逻辑在MyDeploymentAddedHandler实现。
@Component(value = MyDeploymentActionHandler.RESOURCE_NAME + CrdAction.ADDED)
@Slf4j
public class MyDeploymentAddedHandler implements MyDeploymentActionHandler {
@Autowired
private KubeClientDelegate delegate;
@Override
public void handle(MyDeployment myDeployment) {
log.info("{} added", myDeployment.getMetadata().getName());
// TODO 当第一次启动项目时,现存的MyDeployment会回调一次Added事件,这里会导致重复创建pod【可通过status解决】,目前解法是去查一下现存的pod[不可靠]
// 有可能pod的状态还没来得及置为not ready
int existedReadyPodNumber = delegate.client().pods().inNamespace(myDeployment.getMetadata().getNamespace()).withLabelSelector(myDeployment.getSpec().getLabelSelector()).list().getItems()
.stream().filter(UnifiedPodWatcher::isPodReady).collect(Collectors.toList()).size();
Integer replicas = myDeployment.getSpec().getReplicas();
for (int i = 0; i < replicas - existedReadyPodNumber; i++) {
Pod pod = myDeployment.createPod();
log.info("Thread {}:creating pod[{}]: {} , {}", Thread.currentThread().getId(), i, pod.getMetadata().getName(), pod);
delegate.client().pods().create(pod);
}
}
}
这里需要解释一下为什么创建pod的数量需要减去existedReadyPodNumber。经观察发现,如果现存有CRD实例,然后启动Controller,会立即收到CRD的added事件,即使Pod都是健康的,这会导致创建出双倍的Pod。所以这里需要判断一下现存的Pod数量,如果够了,就不去创建了。
但是这又会引入一个问题,假如我将MyDeployment删掉了,此时会级联删除关联的Pod,在没来得及删掉之前,又去创建一个新的MyDeployment,这时候会发现现存的Pod数量并非为0,所以新建的Pod数量就不能达到replicas。解决办法是去判断一下Pod的状态,如果是NotReady,那么就不算是正常的Pod。
但这种解决思路还是有问题,在删掉MyDeployment之后不会立即将Pod状态置为NotReady,需要一定时间,在这段时间内如果创建MyDeployment,那么还是有可能会出现少创建Pod的情况。
目前还没有什么无BUG的思路。
创建一个Pod的实现,将这段代码放到了MyDeployment中,以表示从属关系(代码也好写一些)。
如果Pod是从属于某个MyDeployment,那么我们应该将OwnerReference传入;
Pod的name必须以MyDeployment的name为前缀,后面加上唯一ID;
Pod的spec必须与MyDeployment的spec中的pod template一致;
Pod的labels中包含MyDeployment的label,并且要加上一个pod-template哈希值,以在更新资源时判断pod template是否改变,如果没有变化,则不触发modified事件。
Note: A Deployment’s rollout is triggered if and only if the Deployment’s pod template (that is,
.spec.template) is changed, for example if the labels or container images of the template are updated. Other updates, such as scaling the Deployment, do not trigger a rollout.
public Pod createPod() {
int hashCode = this.getSpec().getPodTemplateSpec().hashCode();
Pod pod = new PodBuilder()
.withNewMetadata()
.withLabels(this.getSpec().getLabelSelector().getMatchLabels())
.addToLabels("pod-template-hash", String.valueOf(hashCode > 0 ? hashCode : -hashCode))
.withName(this.getMetadata().getName()
.concat("-")
.concat(UUID.randomUUID().toString()))
.withNamespace(this.getMetadata().getNamespace())
.withOwnerReferences(
new OwnerReferenceBuilder()
.withApiVersion(this.getApiVersion())
.withController(Boolean.TRUE)
.withBlockOwnerDeletion(Boolean.TRUE)
.withKind(this.getKind())
.withName(this.getMetadata().getName())
.withUid(this.getMetadata().getUid())
.build()
)
.withUid(UUID.randomUUID().toString())
.endMetadata()
.withSpec(this.getSpec().getPodTemplateSpec().getSpec())
.build();
return pod;
}
更新MyDeployment的实现逻辑
更新时主要考虑了两种情况:缩扩容和更新镜像。
通过判断目前Pod数量和MyDeployment中spec的replicas中是否相同来判断是否需要缩扩容。
通过判断是否存在Pod与MyDeployment的container列表是否相同来判断是否需要更新镜像。
如果仅需要更新镜像,则进行rolling-update;
如果仅需要缩扩容,则进行scale;
如果都需要,则先对剩余Pod进行rolling-update,再对缩扩容的Pod进行缩扩容。
rolling-update是滚动升级,一种简单的实现是先扩容一个Pod(新的镜像),再缩容一个Pod(老的镜像),如此反复,直到全部都是新的镜像为止。
public void handle(MyDeployment myDeployment) {
log.info("{} modified", myDeployment.getMetadata().getName());
PodList pods = delegate.client().pods().inNamespace(myDeployment.getMetadata().getNamespace()).withLabelSelector(myDeployment.getSpec().getLabelSelector()).list();
int podSize = pods.getItems().size();
int replicas = myDeployment.getSpec().getReplicas();
boolean needScale = podSize != replicas;
boolean needUpdate = pods.getItems().stream().anyMatch(pod -> {
return myDeployment.isPodTemplateChanged(pod);
});
log.info("needScale: {}", needScale);
log.info("needUpdate: {}", needUpdate);
// 仅更新podTemplate
if (!needScale) {
syncRollingUpdate(myDeployment, pods.getItems());
} else if (!needUpdate) {
// 仅扩缩容
int diff = replicas - podSize;
if (diff > 0) {
scaleUp(myDeployment, diff);
} else {
// 把列表前面的缩容,后面的不动
scaleDown(pods.getItems().subList(0, -diff));
}
} else {
// 同时scale&update
// 对剩余部分做rolling-update,然后对diff进行缩扩容
syncRollingUpdate(myDeployment, pods.getItems().subList(0, Math.min(podSize, replicas)));
int diff = replicas - podSize;
if (diff > 0) {
scaleUp(myDeployment, diff);
} else {
scaleDown(pods.getItems().subList(replicas, podSize));
}
}
}
值得注意的一点是,所有CRUD的APi均为REST调用,是Kubernetes API Server将对象的期望状态写入到ETCD中,然后由kubelet监听事件,去执行变更。
这一点在rolling-update过程中要格外注意,”先扩容,后缩容“中后缩容的前提是扩容成功,即新的Pod创建成功,且状态变为Ready。所以仅仅调用一下create接口是不够的,需要等待直至Ready;删除同理。
private void syncRollingUpdate(MyDeployment myDeployment, List<Pod> pods) {
pods.forEach(oldPod -> {
Pod newPod = myDeployment.createPod();
log.info("Thread {}: pod {} is creating", Thread.currentThread().getId(), newPod.getMetadata().getName());
delegate.createPodAndWait(newPod, myDeployment);
log.info("Thread {}: pod {} is deleting", Thread.currentThread().getId(), oldPod.getMetadata().getName());
delegate.deletePodAndWait(oldPod);
});
}
public void createPodAndWait(Pod pod, MyDeployment myDeployment) {
client.pods().create(pod);
CountDownLatch latch = new CountDownLatch(1);
modifiedPodLatchMap.put(pod.getMetadata().getUid(), latch);
try {
latch.await(TIME_OUT, TimeUnit.SECONDS);
} catch (InterruptedException e) {
log.error("{}", e);
}
log.info("createPodAndWait wait finished successfully!");
}
这里是await阻塞等待,当前类也实现了PodModifiedWatcher接口,countDown是在Pod状态变更时触发。
当Pod被创建后,往往会触发两个事件,第一个是Added,状态是NotReady,第二个是Modified,状态是Ready。这里我们检测到新增的Pod正常运行后,去唤醒执行rolling-update的线程,以实现createPodAndwait的效果。
@Override
public void onPodModified(Pod pod) {
if (UnifiedPodWatcher.isPodReady(pod)) {
CountDownLatch latch = modifiedPodLatchMap.remove(pod.getMetadata().getUid());
if(latch != null) {
latch.countDown();
}
}
}
缩扩容的逻辑比较简单,不需要做等待。
/**
* @param myDeployment
* @param count 扩容的pod数量
*/
private void scaleUp(MyDeployment myDeployment, int count) {
for (int i = 0; i < count; i++) {
Pod pod = myDeployment.createPod();
log.info("scale up pod[{}]: {} , {}", i, pod.getMetadata().getName(), pod);
delegate.client().pods().create(pod);
}
}
/**
* @param pods 待删掉的pod列表
*/
private void scaleDown(List<Pod> pods) {
for (int i = 0; i < pods.size(); i++) {
Pod pod = pods.get(i);
log.info("scale down pod[{}]: {} , {}", i, pod.getMetadata().getName(), pod);
delegate.client().pods().delete(pod);
}
}
删除MyDeployment的实现逻辑
其实就是没有逻辑=.=
Kubernetes的逻辑是删掉了一个资源时,如果其他资源的Metadata中的ownerReference中引用该资源,那么这些资源会被级联删除,这个行为是可以配置的,并且默认为true。
所以我们不需要在此处做任何事情。

没有Go语言版本吗